Multi-Modal Requirements Data-based Acceptance Criteria Generation using LLMs
The Reality, Challenge & Our Solution
"Manual acceptance testing often fails to capture how the system truly behaves across text and visuals. By generating acceptance criteria directly from screenshots and textual requirements, this method bridges this gap — turning what users see and what they expect into automated, verifiable tests."
— A Software Analyst from Monash eSolutions
The Problem: Manual Approach
- Absence of UI-specific details in textual requirements.
- Time-Costing for analysts to conduct domain research.
- Incorrect software understanding based on incomplete information.
- Inconsistent domain knowledge across different developers.
Our Solution: RAGcceptance_M2RE
- Multi-modal: Leverages both Text + UI Screenshots.
- Fast: Generates comprehensive Acceptance Criteria (ACs) in seconds.
- Accurate: Retrieves relevant domain documents to ground the output.
- Stable: Includes a quality check and polish step to refine results.
Core Research Question
Can we automate AC generation by leveraging multi-modal requirements (text + UI) with RAG-enhanced LLMs to reduce manual effort while maintaining quality?
Key Impact
Our approach achieves an ≈50% improvement on @Hit and @Correct accuracy versus the baseline. Experts rated the generated criteria at nearly 4/5 and expressed strong deployment interest.
Technical Challenges & Key Contributions
Challenges
- UI information is difficult to coordinate with textual information in acceptance testing.
- Lack of software context and domain knowledge leads LLMs to produce surface-level outputs.
- LLM "hallucinations" (making up facts) harm the trustworthiness of the output.
Key Contributions
- Multi-Modal RAG: First to employ multi-modal requirements (text and UI) for AC generation. [1]
- Reward Refinement: Uses Local & Global reward models to iteratively improve AC quality. [1]
- Industrial Context: Validated on a large, 100K-User project at Monash eSolutions. [1]
- LLM & Expert Evaluation: A comprehensive automated evaluation combined with expert demonstrations. [1]
RAGcceptance_M2RE: Our Three-Stage Approach
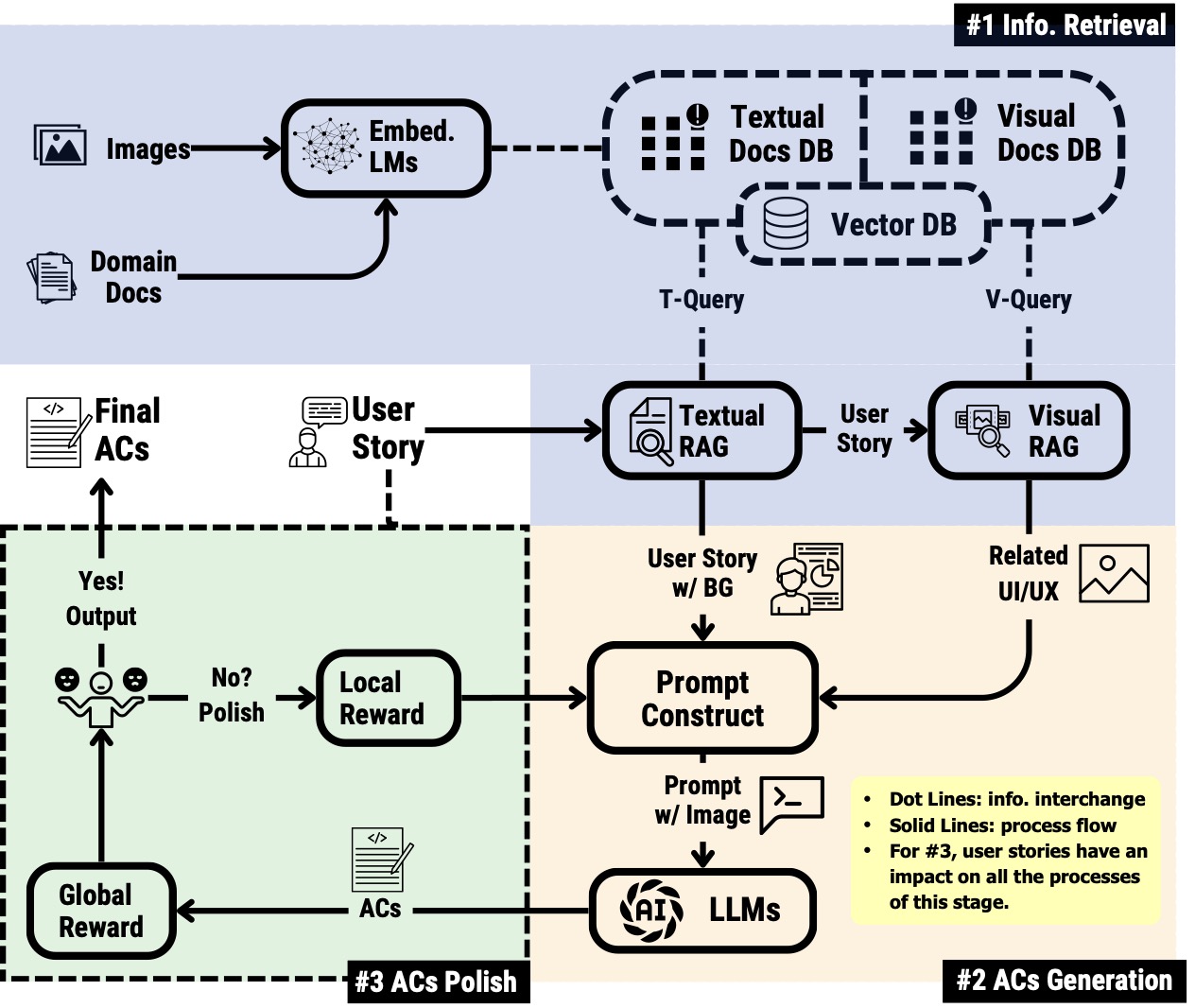
Stage 1: Domain Information Retrieval
- T-RAG (Textual): The ICRALM model retrieves the top-5 most relevant paragraphs from domain documents (e.g., specs, design docs, user guides) using semantic similarity.
- V-RAG (Visual): The DSE model retrieves relevant UI screenshots that show actual system behavior and interface elements.
- Purpose: To ground the LLM in authentic project knowledge and prevent hallucination. [1]
Stage 2: Acceptance Criteria (AC) Generation
- CoT Prompting: APEER/Urial prompting templates guide the LLM's reasoning through a strict Given-When-Then structure.
- Multi-modal LLMs: Models (like Claude Sonnet 3.5, Gemini 2.0 Flash, GPT-4o) process both the retrieved text and the UI screenshots.
- Output: A set of initial ACs that combine textual requirements and visual UI constraints.
Stage 3: Reward-based Polish
- Mechanism: A reward model checks the quality of the generated ACs from both a story-level (Global) and criteria-level (Local) perspective.
- Global Reward: Prometheus (on a 1-5 scale) evaluates the overall quality and coherence of the entire AC set.
- Local Reward: UR3 and Generative Verifier score individual AC statements.
- Iterative Refinement: Any low-scoring ACs are automatically rewritten and re-checked until the quality threshold is met.
Key Results: Rigorous Industrial Evaluation
RQ1: Does Multi-Modal RAG Improve AC Generation?
Takeaway: Yes. Multi-modal RAG boosts case-level accuracy by +23.2pp (42.8% → 66.0%) and point-level by +21.5pp (36.4% → 57.9%). Visual information (V-RAG) alone contributes +6.4pp beyond text-only, proving UI screenshots are essential for accurate AC generation.
RQ2: Does Reward-based Polishing Improve Quality?
Takeaway: Yes. The reward-based polishing step provides an additional accuracy boost, improving case-level accuracy by +7.9pp (71.19% → 79.10%) and point-level by +6.5pp (68.6% → 74.1%).
RQ3: Do Practitioners Find Generated ACs Useful?
Takeaway: Yes. Three senior experts (10–15 years experience) from eSolutions evaluated 81 ACs. They rated them highly (nearly 4/5) across all quality dimensions, including Understandability (4.21/5), Relevance (3.99/5), Correctness (3.94/5), and Coverage (3.89/5). The system successfully captured domain-specific details (like UI information) absent from the user stories and generated criteria that even senior experts wouldn't initially consider. All experts expressed strong deployment interest.
Expert Feedback: Real-World Impact
Three experienced practitioners (10-15 years in software testing & requirements engineering) from eSolutions evaluated our system on 17 real user stories from the UniLearn LMS:
"It's amazing how your system is able to capture 'bento box' [a UI design concept completely absent from the user story text]. This level of detail would take me hours of manual documentation review and UI inspection to identify."
— Senior Business Analyst (10 years)
"This would be really useful for a new BA joining our team. Instead of spending weeks learning our system's domain-specific terminology and UI patterns, they could generate accurate ACs from day one. This significantly reduces onboarding time."
— Requirements Engineer (12 years)
"This also gives some ACs which even as an expert I wouldn't have thought of initially. The multi-modal retrieval surfaces edge cases and UI-specific constraints that are documented somewhere but easy to miss. This improves test coverage."
— QA Architect (15 years)
References and Links
- GitHub Repository: https://github.com/fanyuuwang/Multi_Modal_Requirements_Data_based_Acceptance_Criteria_Generation_using_LLMs [1]
- arXiv Paper: https://arxiv.org/abs/2508.06888